|
|
|

|
Recogniform CHR Engine is the recognition engine developed by Recogniform Technologies to convert handwritten cursive words in ASCII characters. The acronym CHR stands for "Cursive Handwritten Recognition" and indicates the technology of hand-written italic text recognition (not in capital letters: for capital letters see ICR recognition engine at www.recogniform.com/icr.htm ). Developed in collaboration with prestigious universities and laboratories, Recogniform CHR engine has taken more than 3 years of search and experimentation before becoming a product. CHR Technologies: On-line and Off-line The recognition of the on-line writing applies to words written on devices, detecting all movements of the pen. The recognition is performed on vectorial data, made from the coordinates of the ink features and from pen-up/pen-down points. We can easily say that the recognition takes start from a DYNAMIC process of writing. The off-line recognition applies to the the image of the text to recognize. The recognition is performed on data raster, made up of single pixels on/off as from a scanned image. Therefore, we can say that the off-line recognition takes start from a STATIC process of writing, and not DYNAMIC as for the on-line recognition. While it's quite easy to find on-line recognition software (maybe your smartphone already has it), it's hard to find off-line recognition engines. This because of the greater complexity of off-line recognition compared to the on-line recognition. This is due to the fact that off-line recognition has much less information to work with, compared to an on-line handwritten recognition software. Architecture A first subsystem works on image pre-processing: cleaning and normalization of the ink signs. After this step, the subsystem called "unfolding" tries to reconstruct the dynamic sequence of the ink marks as they have been presumablly traced on the paper. This is the most delicate operation: at the end of it the words is divided into a sequence of traces, each of it corresponds to the trace of ink in the period pen-down / pen-up on the paper. The next phase is called "segmentation". It generates the elementary features that correspond to the executed elementary actions of the writer. In fact, according to studies about the generation of the cursive handwritten text, the complex movements necessary to produce a word can be seen like a composition of elementary movements that correspond to elementary shapes, called "strokes". We can say that "stroke" represents the primitive shape that every writer uses in the writing process.
In the next step, "description", each previously identified stroke is labeled according to its change of curving. With the "matching" phase, each stroke is verified against a reference set of interpretations, in order to extract same interpretations from similar sequences of stroke. At last the "classification" subsystem produces the possible interpretations of the word considering all possible combinations of matches obtained from the previous phase and calculating a level of accuracy. This process is very complex, but at its basis there's a simple idea: the idea of being able to recognize words identifying some of the under-sequences using a lookup of ink signs in reference set. A very simple example can be made using a reference set made up of the words " problema" and " valore" , from which being able to recognize the words " prova" , " malore" , " prore" , " mare" , " arma" , " roma" and so on. Of course we need to use different grafemi, since everybody has its own style of writing. So, each grafema needs to be associoated to every possible N-GRAM, according to complex algorithms of probabilities in order to get the correct interpretation of the word. In some cases it is also possible to use dictionaries, in order to peform lookup on a restricted number of possible alternative values.
Recogniform CHR Engine will be available as optional recognition engine for Recogniform Reader soon. Info |

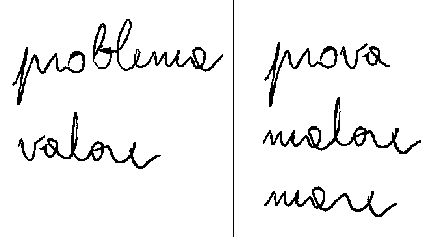
© 2000-2022 Recogniform Technologies SpA - All rights reserved