Recogniform Reader
 Desktop version Workgroup version Desktop version Workgroup version  download .pdf brochure download .pdf brochure  info info
Description
 Recogniform Reader is the innovative solution for the automatic data capture (optical reading) from paper forms. The manual data input often represents the bottle-neck in the processes of forms elaboration and documents filling. Using Recogniform Reader you will immediately and simultaneously get: Recogniform Reader is the innovative solution for the automatic data capture (optical reading) from paper forms. The manual data input often represents the bottle-neck in the processes of forms elaboration and documents filling. Using Recogniform Reader you will immediately and simultaneously get:
-
Lower costs;
-
Higher speed;
-
Quality 100% guaranteed.
Compared to manual data-entry, our data-capture system allows you to use a reduced number of human resources, always operating at the maximum hardware speed, without performance decreasing and errors caused by personnel's tiredness and boring. Using the most advanced technologies, Recogniform Reader is able to achieve results that other products can't obtain and won't probably ever reach.
Fields of application
Thanks to its flexibility, Recogniform Reader is suitable for an wide range of possibilities. Here some:
Technology
Using the state-of-art technologies, Recogniform Reader recognizes all kind of data, thanks to Recogniform recognition engines:
- OMR Technology
 The OMR technology allows user to read the check boxes, that is the sign affixed in predefined spaces. The power of this engine, compared to similar products, is the advantage of working with two operative parameters, evaluating the quantity of existing ink and the size of the sign in the box; The OMR technology allows user to read the check boxes, that is the sign affixed in predefined spaces. The power of this engine, compared to similar products, is the advantage of working with two operative parameters, evaluating the quantity of existing ink and the size of the sign in the box;
- ICR Technology:
 With ICR system it's possible to recognize manuscript data in unconstrained or constrained mode when there is usually space among characters. The engine has been expressly trained on the European and American writing style with an high accuracy. With ICR system it's possible to recognize manuscript data in unconstrained or constrained mode when there is usually space among characters. The engine has been expressly trained on the European and American writing style with an high accuracy.
- BCR Technology:
 The BCR Technology allows the recognition of bar codes, decoding their content. It recognizes all the standard bar codes, enclosed the pharmaceutical ones. The BCR Technology allows the recognition of bar codes, decoding their content. It recognizes all the standard bar codes, enclosed the pharmaceutical ones.
- OCR Technology:

It's the recognition technology for printed and typed texts. It's omnifont and it can recognize characters having any font style and size.
- OCR-A Technology:
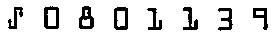 This engine works on pre-printed OCR-A codelines of postal and banking documents; This engine works on pre-printed OCR-A codelines of postal and banking documents;
- OCR-B Technology:
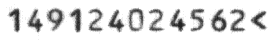 This engine works on pre-printed OCR-B codelines of postal and banking documents; This engine works on pre-printed OCR-B codelines of postal and banking documents;
- MICR CMC7 - E13B Technology:
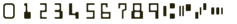 This engines works on pre-printed CMC7 or E13B check codelines. This engines works on pre-printed CMC7 or E13B check codelines.
- CHR Technology:
It allows user to read manuscript data in cursive written (natural writing not in capital letters): what was only imaginary a few years ago, now it's real. This feature is essential for reading forms that haven't been expressly designed for the automatic acquisition and contain unconstrained fields, freely written, without any tie.
- AMK Technology:
The AMR allows you to perform the assisted manual data-entry for data you can't or you don't want to read automatically;
- IDE Technology:
Through the IDE system it's possible to export page zones or whole pages in image format. It's very useful when you need to keep portions of forms containing signatures, sketches, drafts or other information, without modifying anything of their characteristics or structure.
Processing Steps
We can split the forms processing in 4 main steps:
1. Input
2. Recognition
3. Verify/Correction
4. Output
A "zero" step, prior to the production itself, it's represented by the template definition. What is a template? A template is a "project" that contains all rules and information needed to read properly a specific kind of forms. (For example: the template contains the following information: read a barcode Code39 in the upper left of the form).
It's very simple to create and develop a template, using the very easy-to-use tool called Recogniform Application Designer (included in the software): just design with your mouse the fields area on the empty form, select the kind of data you need to extract (barcode, ocr, icr, omr, etc.) and that's all. Of course you can set a lot of functions and rules using a powerful scripting language that will let you feel really the "owner" of the software:discovering its flexibility and power you will soon
imagine a thousand of interesting opportunities.
Desktop or Workgroup?
Recogniform Reader is available in two versions, according to the way the above production steps are executed:
-
Desktop version: all production steps (input, recognition, correction and output) are executed on the same station (pc) one after the other, sequentially.
-
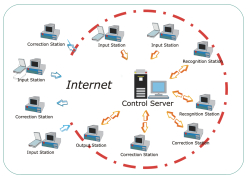 Workgroup version: the steps of input, recognition, correction and output may be splitted on multiple stations, according to your needs. If, for example, you need more resources for correction, you can use multiple
correction stations; the same if you wanna use more scanners with multiple input stations. Workgroup version: the steps of input, recognition, correction and output may be splitted on multiple stations, according to your needs. If, for example, you need more resources for correction, you can use multiple
correction stations; the same if you wanna use more scanners with multiple input stations.
The communication between stations and server is TCP/IP based. In this way the Workgroup is suitable and ready for internet use, allowing you to place the stations in different locations. One
of the many applications is the opportunity to have many operators working at home. At the same time, You could also acquire the input forms with no need to move them phisically from the place they are kept.
Both versions use a a job-oriented approach, grouping documents in batches. A batch can contain any number of documents. Each batch's process is structured as follows:
- Images input (scanning or importing files)
- Pre-processing (deskew, despeckle, form-removal, etc.)
- Automatic reading (CHR, OCR, ICR, BCR, OMR, etc.)
- Suspicious characters verification (Eye Blow Verification®)
- Fields correction (comparison between data and image)
- Post-processing (data transformation and normalization)
- Data output (storing in files or in databases).
Main Features
In order to better explain the main features of Recogniform Reader, let's follow a "step by step" approach, following the production steps described above. For more details on technical infos, please give a look to the specific pages of Recogniform Desktop and Recogniform Workgroup Reader.
Step 0. Template definition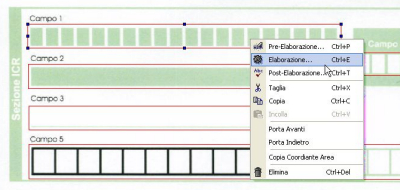
-
Definition of fields areas
-
Simple Visual interface
-
Definition of form global parameters
-
Definition of fields pre-processing parameters
- Definition of fields processing parameters
- Definition of fields post-processing parameters
- Customization via script
- Possibility to implement external DLLs
- Rules for recognition/correction
- Use of not-optimized forms for optical recognition: YES.
c 1. Input
- Input from scanner
- Input from file .TIF, .JPG, .BMP, .PDF
- Input by automatic directory monitoring
- Input by fax
- Input from internet (TCP/IP)
- Set of the batch priority*
- Set of the batch max no. of images*
- Number of Input stations: UNLIMITED*
Step 2. Recognition
-
Setting of advanced pre-processing parameters:
- Color filtering
- Color inversion
- Vertical lines removal
- Horizontal lines removal
- Intrusins removal
- Characters boxes removal
- Field Boxes removal
- Reconnection of crossed characters
- Despeckle
- Black border removal
- Form auto-orientation
- Form auto-alignment
- Global Deskew (form)
- Local deskew (field)
- Characters smoothing
- Dynamic thresholding
- Template auto-identification
- Setting of optical recognition engines:
- BCR recognition engine (Barcode). Speed: UNLIMITED
- ICR recognition engine (handwritten chracters). Speed: UNLIMITED
- OCR recognition engine (printed text). Speed: UNLIMITED
- OCR recognition engine (printed text with OCR-A/B font). Speed: UNLIMITED
- MICR CMC7/E13B recognition engine (codelines printed with CMC7/E13B font). Speed: UNLIMITED
- CHR recognition engine (curive handwritten text). Speed: UNLIMITED
 Step 3. Correction Step 3. Correction
- E.B.V.® (Eye Blow Verification)
- Visual assisted verify
- Text-to-Speech integrated
- Trigrams
- Dynamic Look-up
- Link to every DBMS
- Compressed dictionaries
- Rules customizable via script
- Overlay (see the form with blind colors)
- Number of Correction stations: UNLIMITED*
Step 4. Output
- Release data and normalization;
- Save images in the preferred directory
- Statistics per form, user, day, etc.
- Release data on files:
- .txt, .csv, .xls, .html, .htm, .pdf, .mdb, .tab, .slk, .sylk, .xml, .tsv, .sql, .dbf, .db, pdf ricercabile
- Release data on database
- Oracle, Interbase, Sybase, SQL Server, Access, ODBC Compatibili, Paradox, dBase, FoxPro, Db2
* available only in the Workgroup version

Go to the page of Recogniform Desktop Reader
Go to the page of Recogniform Workgroup Reader
Download .pdf brochure (348KB)
Ask for more info
|
